
【正規化って】第61回シェル芸勉強会【何だったっけ】
今回もいつも通りのリモートでの参加となりました。問題の難易度については、データの正規化がからんだ最終問(Q7)を除けば一時見られた理不尽なほどの難しさはなく、頑張ればなんとか解けるといった感じでした。
- 名称: jus共催 第61回しれっと奇数月に移行しつつあるシェル芸勉強会
- 開催日: 2022年9月24日(土)
- アナウンスページ:
- リンク集: https://b.ueda.tech/?post=shellgei_61_link
- Youtubeライブ配信録画: https://www.youtube.com/watch?v=tiknvvv3SMs
-
問題で使われているデータファイルの入手方法:
git clone https://github.com/ryuichiueda/ShellGeiData.git
Q1
次のデータは、A、B、C君がどこかに出入りした記録なのですが、矛盾している箇所があります。誰のデータが矛盾しているでしょうか?
A 入
C 入
B 入
B 出
A 出
C 入
B 入
B 出
C 出
A1
# `sort -k1,1d -k2,2r`: 1列目を「A、B、C」、2列目を「入、出」の順でソート
$ sort -k1,1d -k2,2r inout | uniq -c | xargs -n6 | awk '$1!=$4' | xargs -n3 | sort -k1,1nr | awk 'NR==1{print $2,$3}'
C 入
Q2
ファイルdataから、3行連続で文字が記述されているところだけ抽出してください。
$ cat data
abc de
fg
hi
あいうえお かきくけこ さしす
せ
そ
UN
KO
上田
山田
上田
山田
不労
所得
わうぃううぇを
うぇうぇうぇうぇw
0000
A2
$ sed '1s/^/\n/;$s/$/\n/' data | tr '\n' : | sed 's/::/\n/g' | sed 's/^://' | awk -F: 'NF==3' | tr : '\n'
abc de
fg
hi
あいうえお かきくけこ さしす
せ
そ
わうぃううぇを
うぇうぇうぇうぇw
0000
Q3
次のnumsファイルについて、cat nums | からはじめて、適切にスペースを入れて1から100まで横に並んだデータに変換してください。途中でnumsのデータを捨てる等のズルは禁止です。
A3
$ cat nums | sed 's/^/0/' | grep -o .. | sed '2,5s/./&\n/;1s/0//;$s/$/0/' | xargs
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100
Q4
file1の最後の改行をとってください。様々な方法を考えてみましょう。
$ cat file1
abc
def
ほげ
A4
$ sed -z 's/\n$//' file1
abc
def
ほげ
解答例を見ただけでは違いがわからないので、xxdに渡して確認します。
# 改行は「0a」
$ cat file1 | xxd -p
6162630a6465660ae381bbe381920a
$ sed -z 's/\n$//' file1 | xxd -p
6162630a6465660ae381bbe38192
Q5
つぎのnums2について、偶数を2行目に移動してください。nums2を開くのは1回とします。
できる人は、1と2以外の数字を使わないでください。もっとできる人は、数字を使わないでください。
$ cat num2
12423285230975943
出力例を示します。
1 3 5 3 9759 3
242 28 2 0 4
A5
$ sed 's/./&_/g;s/_$//;s/.*/&\n&/' nums2 | awk 'BEGIN{FS=OFS="_"}NR==1{for(i=1;i<=NF;i++){$i=$i%2?$i:" "};print}NR==2{for(i=1;i<=NF;i++){$i=$i%2?" ":$i};print}' | tr -d _
1 3 5 3 9759 3
242 28 2 0 4
Q6
次のファイルの数字について、3個先に3倍の数がある数を抽出してください。awk以上の高級な言語を使う場合は、forやwhile等の使用は禁止します。
$ cat nums3
759 355 639 954 640 980 946 237 591 774 711 301 263 791 371 444 599 953 924 657 6 923 424 ...
A6
$ awk '{for(i=1;i<NF-3;i++){if($i*3==$(i+3))print $i}}' nums3
237
284
9
forやwhile等の使用を禁止した別解は次のようになります。
$ f=nums3; paste <(grep -Po '\d+' "$f") <(grep -Po '\d+' "$f" | sed 's/.*/&*3/' | bc) <(grep -Po '\d+' "$f" | sed '1,3d') | grep -P '^\d+\t(\d+)\t\1$' | sed 's/\t.*//'
237
284
9
Q7
次のようにpriorというファイルを作ってください。
$ seq 0 100 | awk '{print $1/100, 1/101}' > prior
$ cat prior
0 0.00990099
0.01 0.00990099
0.02 0.00990099
・・・
0.98 0.00990099
0.99 0.00990099
1 0.00990099
Q7小問1
このファイルについて、
echo 表 | while read c ; ... ; done
echo 裏 | while read c ; ... ; done
の...のところにコードを追加して、次の操作をして、列をひとつ足してください。ただし、awkを使う場合は$2, $3, $4, ...を使わず、代わりに$NFを使ってください。$1だけ使って構いません。
- 「表」なら最終列に「1列目と2列目の数をかけて、3列目に追加し、3列目の合計が1になるように正規化する。」
- 「裏」なら最終列に「(1.0 - 1列目の数)と2列目の数をかけて、3列目に追加し、3列目の合計が1になるように正規化する。」
出力はつぎのようになるはずです。
$ echo 表 | while read c ; do ... ; done
0 0.00990099 0
0.01 0.00990099 0.00019802
0.02 0.00990099 0.00039604
0.03 0.00990099 0.000594059
0.04 0.00990099 0.000792079
・・・
$ echo 裏 | while read c ; do ... ; done
0 0.00990099 0.019802
0.01 0.00990099 0.019604
0.02 0.00990099 0.0194059
0.03 0.00990099 0.0192079
0.04 0.00990099 0.0190099
・・・
Q7小問2
coinというファイルがあります。
$ cat coin
表裏表表
小問1のワンライナーを改造して、coinの裏表の順に、priorに1列ずつ列を足していってください。上書きして構いません。出力例を示します。
$ tail prior
0.91 0.00990099 0.0180198 0.00491449 0.00894437 0.0135665
0.92 0.00990099 0.0182178 0.00441644 0.00812625 0.0124611
0.93 0.00990099 0.0184158 0.00390638 0.00726587 0.0112629
0.94 0.00990099 0.0186139 0.00338435 0.00636258 0.00996871
0.95 0.00990099 0.0188119 0.00285029 0.00541555 0.00857519
0.96 0.00990099 0.0190099 0.00230423 0.00442412 0.00707906
0.97 0.00990099 0.0192079 0.00174617 0.00338757 0.00547694
0.98 0.00990099 0.0194059 0.00117612 0.0023052 0.00376541
0.99 0.00990099 0.019604 0.000594061 0.00117624 0.00194093
1 0.00990099 0.019802 0 0 0
最終列についてグラフを描くと次のようになっているはずです。
$ cat prior | gnuplot -e 'set terminal png;set output "./ouoo.png";plot "-" using 1:6'
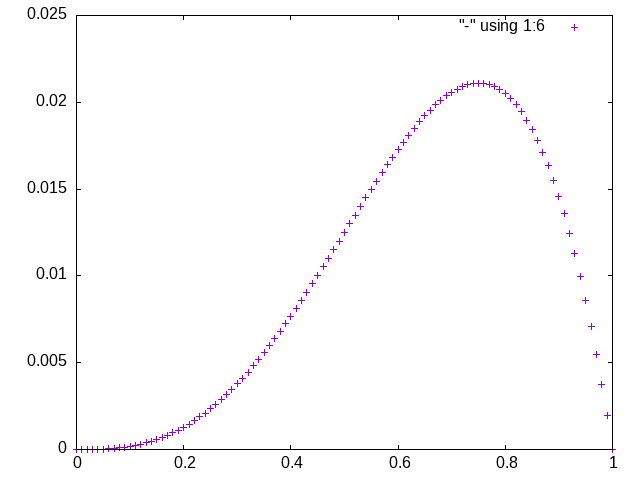
A7
A7小問1
# 3列目の合計が1になるように正規化(3列目の各行の値÷3列目の合計)するために、
#
# 1. 1つ目の`awk ... '{v=c=="表"?$1*$NF:(1.0-$1)*$NF ... }'`で合計を取得
# 2. 2つ目の`awk ... '{v=c=="表"?$1*$NF:(1.0-$1)*$NF ... }'`で正規化
$ echo 表 | while read c ; do s=$(awk -v c=$c '{v=c=="表"?$1*$NF:(1.0-$1)*$NF;s+=v}END{print s}' prior) ; awk -v c=$c -v s=$s '{v=c=="表"?$1*$NF:(1.0-$1)*$NF;print $0,v/s}' prior ; done
0 0.00990099 0
0.01 0.00990099 0.00019802
0.02 0.00990099 0.00039604
0.03 0.00990099 0.000594059
0.04 0.00990099 0.000792079
0.05 0.00990099 0.000990099
0.06 0.00990099 0.00118812
0.07 0.00990099 0.00138614
0.08 0.00990099 0.00158416
0.09 0.00990099 0.00178218
(...略...)
$ echo 裏 | while read c ; do s=$(awk -v c=$c '{v=c=="表"?$1*$NF:(1.0-$1)*$NF;s+=v}END{print s}' prior) ; awk -v c=$c -v s=$s '{v=c=="表"?$1*$NF:(1.0-$1)*$NF;print $0,v/s}' prior ; done
0 0.00990099 0.019802
0.01 0.00990099 0.019604
0.02 0.00990099 0.0194059
0.03 0.00990099 0.0192079
0.04 0.00990099 0.0190099
0.05 0.00990099 0.0188119
0.06 0.00990099 0.0186139
0.07 0.00990099 0.0184158
0.08 0.00990099 0.0182178
0.09 0.00990099 0.0180198
(...略...)
A7小問2
# 上書きするので`prior`をコピー
$ cp prior prior.bak
# バージョン4.1.0以降のGNU Awkではオプションに`-i inplace`を指定することで上書き保存が可能
$ grep -o . coin | while read c ; do s=$(awk -v c=$c '{v=c=="表"?$1*$NF:(1.0-$1)*$NF;s+=v}END{print s}' prior) ; awk -i inplace -v c=$c -v s=$s '{v=c=="表"?$1*$NF:(1.0-$1)*$NF;print $0,v/s}' prior ; done
$ tail prior
0.91 0.00990099 0.0180198 0.00491449 0.00894437 0.0135665
0.92 0.00990099 0.0182178 0.00441644 0.00812625 0.0124611
0.93 0.00990099 0.0184158 0.00390638 0.00726587 0.0112628
0.94 0.00990099 0.0186139 0.00338435 0.00636258 0.00996871
0.95 0.00990099 0.0188119 0.00285029 0.00541555 0.00857519
0.96 0.00990099 0.0190099 0.00230423 0.00442412 0.00707906
0.97 0.00990099 0.0192079 0.00174617 0.00338757 0.00547694
0.98 0.00990099 0.0194059 0.00117612 0.0023052 0.00376541
0.99 0.00990099 0.019604 0.000594061 0.00117624 0.00194093
1 0.00990099 0.019802 0 0 0
なお、最終列のグラフは次のようになります。
$ cat prior | gnuplot -e 'set terminal png;set output "./A7-2.png";plot "-" using 1:6'